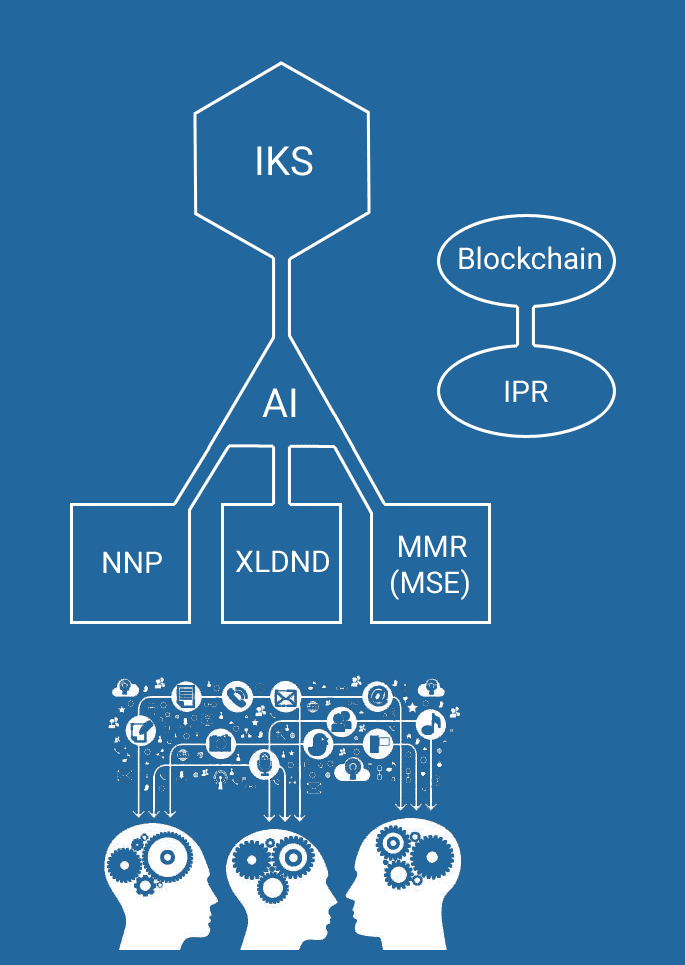
Technology
Babel Jumper’s commercial project is based on the integration in a single system of the three technologies described below. Thai is made possible by the implementation of a unifying software (kernel), that concretely realizes what Giano has been designing since the beginning of the millennium, when in Lisbon it was officially enunciated by the member countries of the European Union the principles which gave the “knowledge” the destinies of economic development.
New criteria for cataloging, storing and distributing textual contents, as shown in the resident data base and on the Web, through the use of the Search Meta-engine, enables the user to draw on the “static sources” of knowledge, while the daily update of the information coming from “Certified dynamic sources” enriches the knowledge baggage for any of the subjects of interest.
The development of infrastructural software, user interfaces, definition of the semantic contexts (or linguistic domains) and development of the languages will be entrusted to Giano’s historical project team, while Babel Jumper will manage the whole system as an efficient company organization.
Main markets our technologies are addressed to are several:
- knowledge users (high school students and universities)
- Researchers from public and private institutes
- Industrial researchers and knowledge operators (publishers and of newspapers editors)
- Training centers
The involvement of publishing houses of newspapers and publishers of magazines and specialized periodicals will be done through agreements among them and Babel Jumper as well as with research institutions, university libraries and schools.
The adoption of block-chain technology, together with the fractional distribution of editorial content will extend the market to publishers in each country, while the metalinguistic semantic and collaborative feature of the Meta-engine opens up new perspectives to all advertisers.
